Setting up monitoring and tracing for legacy systems

Many companies know that their legacy systems need more visibility. Nevertheless, the implementation of monitoring often progresses only slowly in practice. This is rarely due to a lack of tools. More often, there is no clear understanding of what a sustainable monitoring architecture should look like or where to start.
This is precisely where the real problem lies. Collecting as much data as possible as quickly as possible may create visibility, but not understanding. The key is to develop a monitoring architecture in stages, one that is oriented towards real problems and can be used in operations.
Why the implementation of monitoring in legacy systems often fails
Many initiatives start with the right objective, but quickly lose impact. A common pattern is for large volumes of metrics to be collected without prioritisation. Either teams attempt to capture the entire system at once, or a tool is selected without considering architectural constraints, such as network restrictions or lack of access to code.
The result is a flood of data without meaningful insights, and monitoring itself becomes a new source of complexity.
Core principle of a sustainable monitoring architecture for legacy systems
Above all, an architecture for legacy systems must be able to work with existing structures without assuming them.
Even in evolved system landscapes, a monitoring and tracing setup adheres to a clear principle in practice. It can be divided into four layers:
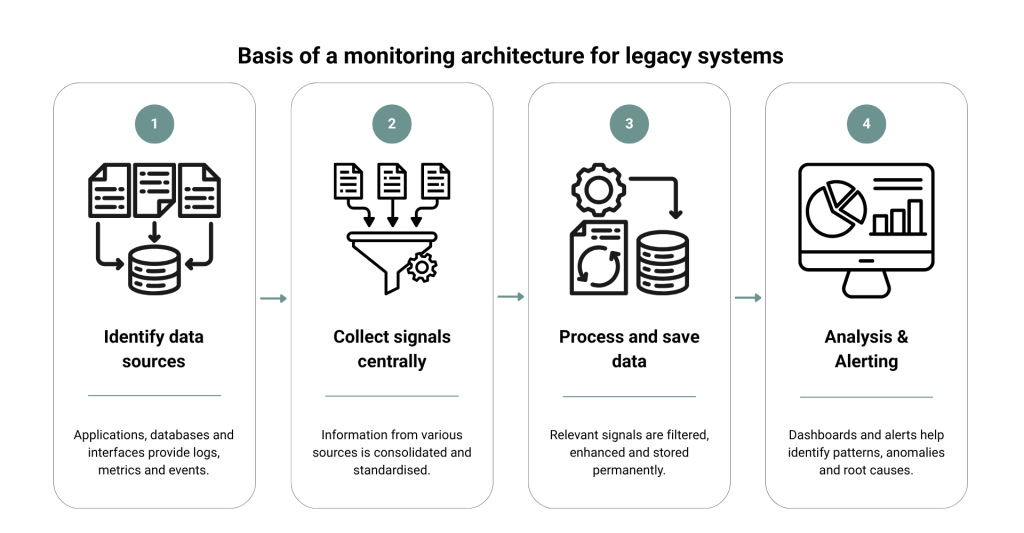
- Data generation (within the system itself)
This is where the relevant information is created, for example in applications, databases or interfaces. This includes, for instance, a Java monolith with an Oracle database, batch processes on mainframe-related systems, or legacy integrations with third-party providers. - Central data collection
An upstream component consolidates information from different sources. This is particularly relevant in environments where systems are not uniformly structured or can only be adapted to a limited extent, such as on-premises applications or components without access to source code. - Processing and storage
The collected data is stored and processed in specialised systems. Different data types are handled separately to enable efficient analysis. - Visualisation and analysis
Dashboards present the data in a way that makes relationships visible. It is only at this stage that it becomes clear how individual components interact and where problems actually arise.
The value of this separation is particularly evident in typical legacy scenarios. For example, if a batch process fails, an external interface responds with delays or an evolved application is under load, the causes can only be reliably identified if these layers are clearly separated.
Without this structure, a system quickly emerges that is difficult to understand itself.
A clear architecture, on the other hand, ensures that monitoring and tracing can be expanded step by step without requiring changes to existing applications with every adjustment.
Which architectural decisions should be made in advance
Before selecting specific technologies, several fundamental questions must be answered. These largely determine whether the resulting solution will be sustainable in the medium term or require adjustment.
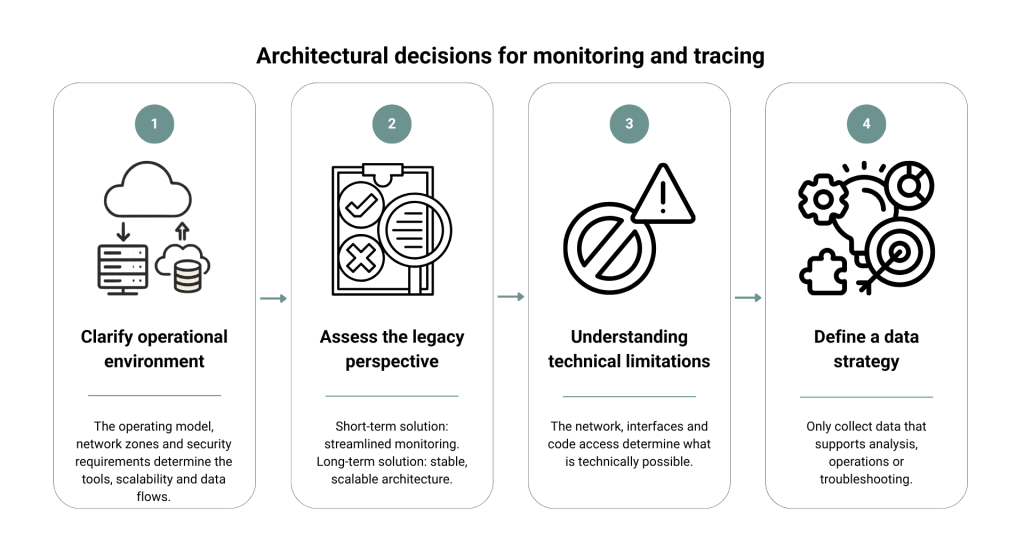
- Step 1: Clarify the operating environment conditions
First, establish where the monitoring will be operated. In cloud-based scenarios, native solutions are suitable and can be deployed quickly. However, this creates a stronger dependency on the respective provider. In on-premises environments, the focus is more on operation, scalability, and integration with existing infrastructure. - Step 2: Evaluate the perspective of the legacy system
Not every system justifies the same level of effort. If a system is likely to be replaced in the medium term, a deliberately lean monitoring approach should be adopted. Systems with long-term relevance, on the other hand, require a more stable and extensible architecture. - Step 3: Assess technical constraints realistically
In legacy systems, existing conditions often determine what is actually possible. Network restrictions, missing interfaces or limited ability to modify code have a direct impact on the architecture. These factors should therefore be considered early on to avoid later adjustments. - Step 4: Define the data strategy
It is important to clarify which data is required and at what level of detail. An unclear data strategy quickly leads to unnecessary complexity. Ideally, reliable insights should be derived from as few relevant data points as possible.
Tool selection in the context of the legacy system landscape
The selection of suitable tools depends heavily on the individual starting situation. The following overview helps to classify typical use cases more effectively.
| Tool / Category | Use Case | Limitations | Typical mistakes in use |
|---|---|---|---|
| Grafana (visualisation) | Particularly suitable for environments where data from different sources needs to be consolidated and displayed centrally. | Dependent on connected data sources; no native data collection. | Dashboards are created without a clear question. Result: visually appealing displays without real value. |
| Prometheus (metrics) | Proven for structured collection and evaluation of metrics, especially in systems with clear integration options. | Integration into older systems can be complex. | Too many metrics are collected without prioritisation. Relevant signals are lost. |
| Datadog (platform solution) | Useful when a quick start with minimal implementation effort is the priority. | Higher costs and stronger vendor lock-in. | The tool is treated as a complete solution without designing a proper architecture. Dependency becomes a problem later. |
| CloudWatch (cloud-native) | Obvious choice in scenarios where systems are already closely tied to a cloud environment. | Limited flexibility in hybrid or migration scenarios. | Usage remains limited to basic functions. More complex relationships are not mapped. |
| OpenTelemetry (tracing/standard) | A good choice if a vendor-independent foundation for collecting telemetry data is required. | Requires initial integration and understanding of the architecture. | Introduction without a clear target state. Data is generated but not meaningfully evaluated. |
Six steps to building monitoring and tracing in legacy systems
The implementation of monitoring and tracing does not follow a rigid scheme. In practice, it only works if both perspectives are considered together from the outset and the solution is oriented towards real problems.
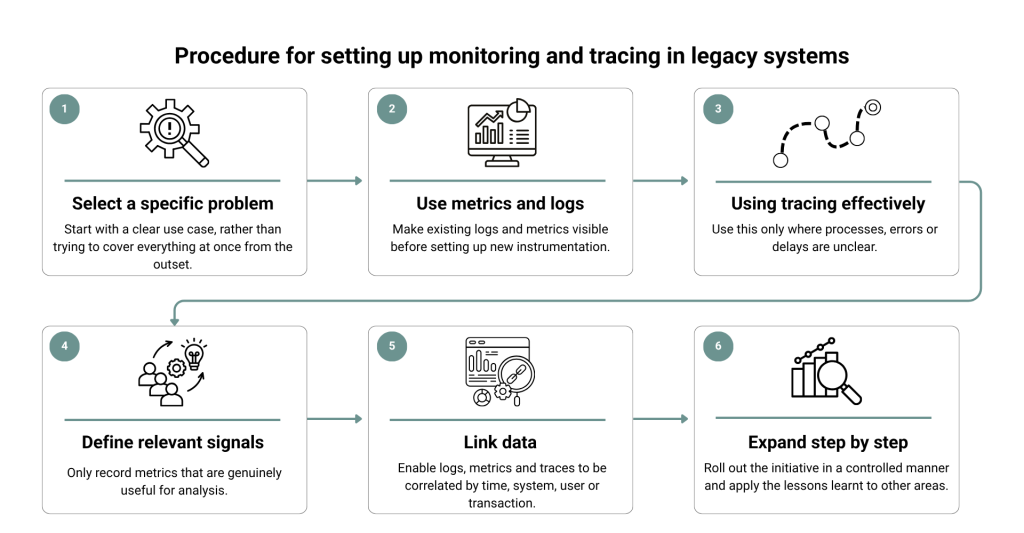
1. Starting point: a specific problem instead of complete transparency
Objective
Identify a clearly defined area where monitoring and tracing provide immediate, tangible value.
Typical misconception
‘We first need to understand and fully map the entire system.’
Recommended approach
Deliberately choose a critical use case, such as an unstable interface or an error-prone process. Formulate a specific question you want to answer. The focus is not on completeness, but on insight.
2. Create initial visibility: metrics and logs as a starting point
Objective
Develop an initial understanding of system behaviour without deeply intervening in the architecture.
Typical misconception
‘Without new tools or instrumentation, monitoring provides no value.’
Recommended approach
Use existing logs and add only the most essential metrics, such as response times or error rates. The goal is to identify initial patterns and form hypotheses, not to build a complete data foundation.
3. Use tracing selectively to make dependencies visible
Objective
Make specific processes traceable and clearly identify bottlenecks.
Typical misconception
‘Tracing should be introduced as early and as comprehensively as possible.’
Recommended approach
Use tracing only where dependencies are unclear. Track individual requests through the system to understand where delays or errors occur. This creates clarity without introducing unnecessary complexity.
4. Define relevant signals instead of increasing data volume
Objective
Establish a manageable set of meaningful metrics that actually support analysis.
Typical misconception
‘The more data we collect, the better we understand the system.’
Recommended approach
Deliberately define which signals are truly relevant. Focus on key indicators such as latency, error rates or utilisation, but only to the extent that they are meaningful for your specific use case. Avoid collecting data without a clear purpose.
5. Make monitoring and tracing usable together
Objective
Quickly identify and understand the relationships between symptoms and causes.
Typical misconception
‘It is sufficient to provide metrics, logs and traces separately.’
Recommended approach
Ensure that data can be linked. An anomaly in a dashboard should lead directly to a detailed analysis. Only when this connection exists will a consistent understanding of the system emerge.
6. Expand step by step and secure insights
Objective
Systematically expand transparency without introducing new complexity to monitoring itself.
Typical misconception
‘Once an approach works, it should quickly be rolled out across the entire system.’
Recommended approach
Expand the approach in a controlled manner. Transfer insights gained to other areas and adjust the approach if necessary. This allows understanding of the system to grow without creating new complexity.
Monitoring in legacy systems as a strategic investment
Implementing monitoring and tracing in legacy systems is a process guided by clear principles. It transforms IT operations from a reactive response mode into a proactive and controllable practice.
A sustainable monitoring stack for legacy systems is not created by using as many tools as possible. Clear priorities and sound architecture are what matter. Those who start with critical areas and expand instrumentation step by step achieve transparency without introducing new complexity.
Would you like to increase the transparency of your systems?
The experts at 7P support you with their extensive experience in selecting the right monitoring stack and integrating it step by step into your system landscape, whether it is a greenfield or a legacy solution.
Contact
Are you looking for an experienced and reliable IT partner?
We offer customised solutions to meet your needs – from consulting, development and integration to operation.
You are currently viewing a placeholder content from Hubspot Embedded Content. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from HubSpot. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Hubspot Meetings. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information