Monitoring und Tracing für Legacy-Systeme aufbauen

Viele Unternehmen wissen, dass ihre Legacy-Systeme mehr Einblick brauchen. Trotzdem kommt der Aufbau von Monitoring in der Praxis oft nur schleppend voran. Das liegt selten an fehlenden Tools. Häufig fehlt eine klare Vorstellung davon, wie eine tragfähige Monitoring-Architektur überhaupt aussehen muss und wo der richtige Einstiegspunkt liegt.
Genau hier liegt das eigentliche Problem. Wer versucht, möglichst schnell viele Daten zu sammeln, schafft zwar Sichtbarkeit, aber noch kein Verständnis. Entscheidend ist, eine Monitoring-Architektur schrittweise aufzubauen, die sich an realen Problemen orientiert und im Betrieb tatsächlich nutzbar ist.
Warum der Aufbau von Monitoring in Legacy-Systemen oft scheitert
Viele Initiativen starten mit dem richtigen Ziel, verlieren dann aber schnell an Wirkung. Ein typisches Muster ist, dass massenhaft Metriken ohne Priorisierung gesammelt werden. Teams versuchen, das gesamte System gleichzeitig zu erfassen, oder es wird ein Tool festgelegt, ohne die Architektur-Einschränkungen (wie Netzwerk-Restriktionen oder fehlenden Code-Zugriff) zu prüfen.
Die Folge ist eine Datenflut ohne Aussagekraft, während das Monitoring selbst zum neuen Komplexitätstreiber wird.
Grundprinzip einer tragfähigen Monitoring-Architektur für Legacy-Systeme
Eine Architektur für Legacy-Systeme muss vor allem mit bestehenden Strukturen umgehen können, ohne sie vorauszusetzen.
Auch in gewachsenen Systemlandschaften folgt ein Monitoring- und Tracing-Setup in der Praxis einem klaren Prinzip. Es lässt sich in vier Ebenen gliedern:
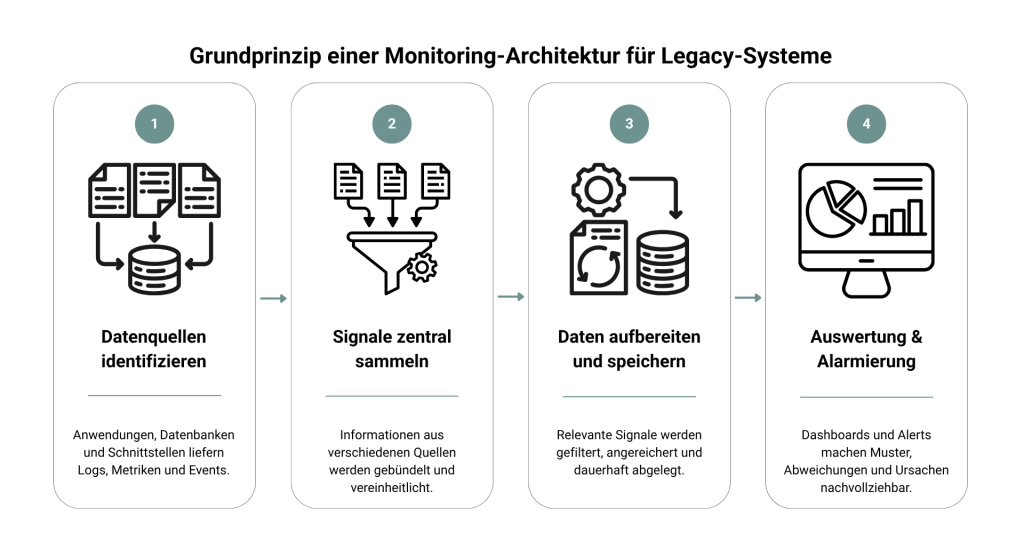
- Datenerzeugung (im System selbst)
Hier entstehen die relevanten Informationen, etwa in Anwendungen, Datenbanken oder Schnittstellen. Dazu gehören beispielsweise ein Java-Monolith mit Oracle-Datenbank, Batchprozesse auf mainframe-nahen Systemen oder auch alte Integrationen zu Drittanbietern. - Zentrale Sammlung der Daten
Eine vorgelagerte Komponente bündelt die Informationen aus unterschiedlichen Quellen. Das ist besonders in Umgebungen relevant, in denen Systeme nicht einheitlich aufgebaut sind oder nur eingeschränkt angepasst werden können, etwa bei On-Prem-Anwendungen oder Komponenten ohne Zugriff auf den Quellcode. - Verarbeitung und Speicherung
Die gesammelten Daten werden in spezialisierten Systemen abgelegt und aufbereitet. Dabei werden unterschiedliche Datentypen getrennt behandelt, um eine effiziente Auswertung zu ermöglichen. - Visualisierung und Analyse
Über Dashboards werden die Daten so zusammengeführt, dass Zusammenhänge sichtbar werden. Erst hier wird erkennbar, wie einzelne Komponenten miteinander interagieren und wo Probleme tatsächlich entstehen.
Gerade in typischen Legacy-Szenarien zeigt sich der Wert dieser Trennung besonders deutlich. Wenn beispielsweise ein Batchprozess fehlschlägt, eine externe Schnittstelle verzögert reagiert oder eine gewachsene Anwendung unter Last steht, lassen sich die Ursachen nur dann zuverlässig eingrenzen, wenn diese Ebenen sauber voneinander getrennt sind.
Fehlt diese Struktur, entsteht schnell ein System, das selbst schwer zu durchdringen ist.
Eine klare Architektur sorgt dagegen dafür, dass sich Monitoring und Tracing schrittweise erweitern lassen, ohne dass bestehende Anwendungen bei jeder Anpassung verändert werden müssen.
Welche Architekturentscheidungen vorab getroffen werden sollten
Bevor konkrete Technologien ausgewählt werden, müssen einige grundlegende Fragen geklärt sein. Diese bestimmen maßgeblich, ob die spätere Lösung tragfähig ist oder mittelfristig angepasst werden muss.
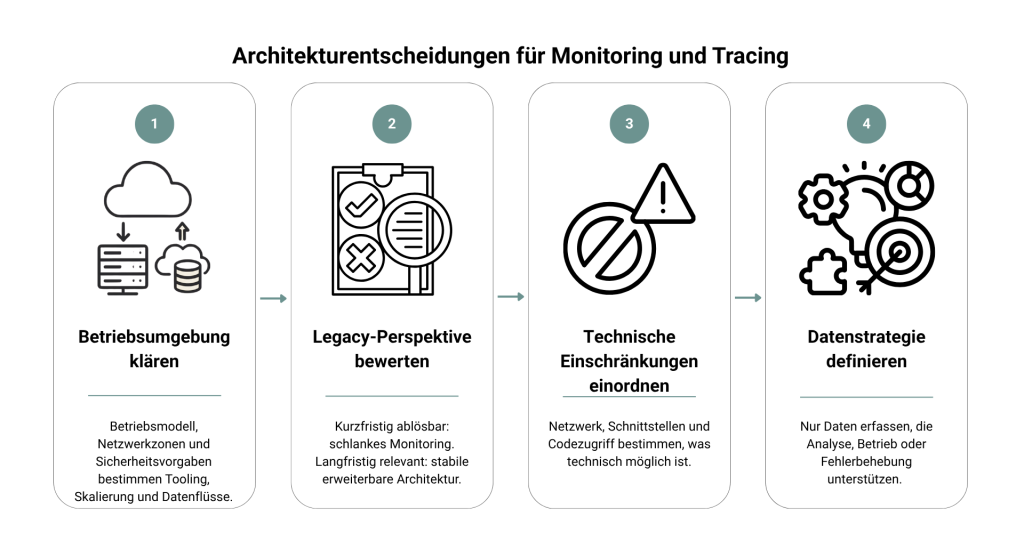
- Schritt 1: Klärung der Rahmenbedingungen der Betriebsumgebung
Zunächst sollte klar sein, in welchem Umfeld das Monitoring betrieben wird. In Cloud-basierten Szenarien bieten sich native Lösungen an, die schnell einsatzbereit sind. Gleichzeitig entsteht dadurch eine stärkere Bindung an den jeweiligen Anbieter. In On-Premise-Umgebungen liegt der Fokus stärker auf Betrieb, Skalierung und Integration in bestehende Infrastrukturen. - Schritt 2: Perspektive des Legacy-Systems bewerten
Nicht jedes System rechtfertigt den gleichen Aufwand. Wenn absehbar ist, dass ein System mittelfristig ersetzt wird, sollte der Monitoring-Ansatz bewusst schlank bleiben. Systeme mit langfristiger Relevanz benötigen dagegen eine stabilere und erweiterbare Architektur. - Schritt 3: Technische Einschränkungen realistisch einordnen
Gerade bei Legacy-Systemen bestimmen oft bestehende Rahmenbedingungen darüber, was überhaupt möglich ist. Netzwerkrestriktionen, fehlende Schnittstellen oder die eingeschränkte Änderbarkeit des Codes haben direkten Einfluss auf die Architektur. Diese Faktoren sollten daher frühzeitig berücksichtigt werden, um spätere Anpassungen zu vermeiden. - Schritt 4: Datenstrategie definieren
Es sollte Klarheit darüber herrschen, welche Daten tatsächlich benötigt werden und in welcher Tiefe. Eine unklare Datenstrategie führt schnell zu unnötiger Komplexität. Idealerweise können mit möglichst wenigen, aber relevanten Datenpunkten belastbare Aussagen getroffen werden.
Tool-Auswahl im Kontext der Legacy-Systemlandschaft
Die Auswahl geeigneter Werkzeuge hängt stark von der individuellen Ausgangssituation ab. Die folgende Übersicht hilft dabei, typische Einsatzszenarien besser einzuordnen.
| Tool / Kategorie | Einsatzkontext | Einschränkungen | Typische Fehler im Einsatz |
|---|---|---|---|
| Grafana (Visualisierung) | Besonders geeignet in Umgebungen, in denen Daten aus verschiedenen Quellen zusammengeführt und zentral dargestellt werden müssen. | Abhängig von den angebundenen Datenquellen, keine eigene Datenerhebung. | Es werden Dashboards gebaut, ohne klare Fragestellung. Ergebnis: schöne Visualisierungen ohne echten Mehrwert. |
| Prometheus (Metriken) | Bewährt für die strukturierte Erfassung und Auswertung von Metriken, vor allem in Systemen mit klaren Integrationsmöglichkeiten. | Integration in ältere Systeme kann aufwendig sein. | Es werden zu viele Metriken gesammelt, ohne Priorisierung. Relevante Signale gehen unter. |
| Datadog (Plattformlösung) | Sinnvoll, wenn ein schneller Einstieg mit möglichst geringem Implementierungsaufwand im Vordergrund steht. | Höhere Kosten und stärkere Anbieterbindung. | Tool wird als Komplettlösung gesehen, ohne eigene Architektur zu durchdenken. Abhängigkeit wird erst spät zum Problem. |
| CloudWatch (Cloud-nativ) | Naheliegend in Szenarien, in denen Systeme bereits eng an eine Cloud-Umgebung gebunden sind. | Eingeschränkt flexibel in hybriden oder migrationsfähigen Szenarien. | Nutzung bleibt auf Basisfunktionen beschränkt. Komplexere Zusammenhänge werden nicht abgebildet. |
| OpenTelemetry (Tracing/Standard) | Gute Wahl, wenn eine anbieterunabhängige Grundlage für die Erfassung von Telemetriedaten geschaffen werden soll. | Erfordert initiale Integration und Verständnis der Architektur. | Einführung ohne klares Zielbild. Daten werden erzeugt, aber nicht sinnvoll ausgewertet. |
In 6 Schritten zum Aufbau von Monitoring und Tracing in Legacy-Systemen
Der Aufbau von Monitoring und Tracing folgt keinem starren Schema. In der Praxis funktioniert er nur, wenn er sich von Anfang an an realen Problemen orientiert und beide Perspektiven zusammengedacht werden.
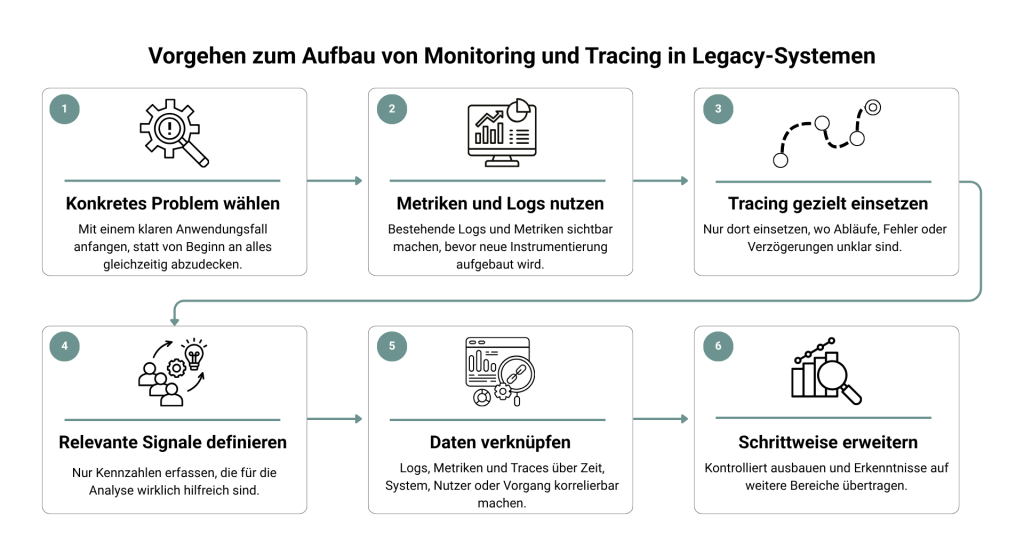
1. Ausgangspunkt: Ein konkretes Problem statt vollständiger Transparenz
Ziel
Einen klar abgegrenzten Bereich identifizieren, in dem Monitoring und Tracing direkt einen spürbaren Mehrwert liefern.
Typische Fehlannahme
„Wir müssen zuerst das gesamte System verstehen und vollständig abbilden.“
Empfohlene Vorgehensweise
Wählen Sie bewusst einen kritischen Anwendungsfall aus, etwa eine instabile Schnittstelle oder einen fehleranfälligen Prozess. Formulieren Sie eine konkrete Fragestellung, die Sie beantworten wollen. Der Fokus liegt dabei nicht auf Vollständigkeit, sondern auf Erkenntnis.
2. Erste Sichtbarkeit schaffen: Metriken und Logs als Einstieg
Ziel
Ein erstes Verständnis für das Systemverhalten entwickeln, ohne direkt tief in die Architektur eingreifen zu müssen.
Typische Fehlannahme
„Ohne neue Tools oder Instrumentierung bringt Monitoring keinen Mehrwert.“
Empfohlene Vorgehensweise
Nutzen Sie vorhandene Logs und ergänzen Sie nur die notwendigsten Metriken, etwa Antwortzeiten oder Fehlerraten. Dabei sollen erste Muster erkannt und Hypothesen gebildet werden und keine vollständige Datengrundlage aufgebaut werden.
3. Tracing gezielt einsetzen, um Zusammenhänge sichtbar zu machen
Ziel
Konkrete Abläufe nachvollziehbar machen und Engpässe eindeutig lokalisieren.
Typische Fehlannahme
„Tracing sollte möglichst früh und flächendeckend eingeführt werden.“
Empfohlene Vorgehensweise
Setzen Sie Tracing nur dort ein, wo Zusammenhänge unklar sind. Verfolgen Sie gezielt einzelne Requests durch das System, um zu verstehen, an welcher Stelle Verzögerungen oder Fehler entstehen. So schaffen Sie Klarheit, ohne unnötige Komplexität aufzubauen.
4. Relevante Signale definieren statt Datenmengen erhöhen
Ziel
Eine überschaubare Menge an aussagekräftigen Kennzahlen etablieren, die tatsächlich zur Analyse beitragen.
Typische Fehlannahme
„Je mehr Daten wir sammeln, desto besser verstehen wir das System.“
Empfohlene Vorgehensweise
Definieren Sie bewusst, welche Signale wirklich relevant sind. Orientieren Sie sich an zentralen Indikatoren wie Latenz, Fehlerraten oder Auslastung, aber nur soweit sie für Ihren konkreten Anwendungsfall sinnvoll sind. Vermeiden Sie es, Daten ohne klaren Zweck zu erfassen.
5. Monitoring und Tracing gemeinsam nutzbar machen
Ziel
Zusammenhänge zwischen Symptomen und Ursachen schnell erkennen und nachvollziehen können.
Typische Fehlannahme
„Es reicht aus, Metriken, Logs und Traces getrennt bereitzustellen.“
Empfohlene Vorgehensweise
Stellen Sie sicher, dass sich Daten miteinander verknüpfen lassen. Ein auffälliger Wert im Dashboard sollte direkt zur Detailanalyse führen können. Erst wenn diese Verbindung besteht, entsteht ein konsistentes Verständnis des Systems.
6. Schrittweise erweitern und Erkenntnisse sichern
Ziel
Transparenz systematisch ausbauen, ohne das Monitoring selbst zu einem neuen Komplexitätsfaktor zu machen.
Typische Fehlannahme
„Sobald ein Ansatz funktioniert, sollte er schnell auf das gesamte System ausgerollt werden.“
Empfohlene Vorgehensweise
Erweitern Sie den Ansatz kontrolliert. Übertragen Sie die gewonnenen Erkenntnisse auf weitere Bereiche und passen Sie das Vorgehen bei Bedarf an. So wächst das Verständnis für das System, ohne dass neue Unübersichtlichkeit entsteht.
Monitoring in Legacy-Systemen als strategische Investition
Die Implementierung von Monitoring und Tracing in Legacy-Systemen ist ein Prozess, der sich an klaren Richtlinien orientiert. Er verwandelt den IT-Betrieb von einem reaktiven Reaktionsmodus in eine proaktive, steuerbare Verwaltung.
Ein tragfähiger Monitoring-Stack für Legacy-Systeme entsteht nicht durch die Verwendung möglichst vieler Tools, vielmehr sind klare Prioritäten und eine saubere Architektur entscheidend. Wer mit den kritischen Bereichen beginnt und die Instrumentierung schrittweise erweitert, schafft Transparenz, ohne neue Komplexität zu erzeugen.
Sie möchten die Transparenz Ihrer Systeme erhöhen?
Die Experten von 7P unterstützen Sie mit ihrer langjährigen Erfahrung dabei, den passenden Monitoring-Stack auszuwählen und schrittweise in Ihre Systemlandschaft zu integrieren. Egal, ob es sich um eine Greenfield- oder eine Legacy-Lösung handelt.
Kontakt
Sie suchen einen erfahrenen und zuverlässigen IT-Partner?
Wir bieten Ihnen individuelle Lösungen für Ihre Anliegen – von Beratung, über Entwicklung, Integration, bis hin zum Betrieb.

Sie sehen gerade einen Platzhalterinhalt von HubSpot. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Hubspot Meetings. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen